Ongoing report on the conversion of the TIPA files received from Mr Arockiasamy
Background and previous steps
In the recent months, Eva has negociated with Mr Ilavazhagan,
who is the man behind the தமிழ் மண் பதிப்பகம்,
the acquisition by NETamil of the editable files
of the 17-vol (+ index)
of the TIPA (தமிழ் இலக்கணப் பேரகராதி)
As part of the negociation,
professor VV, Babu, Thilak and JLC
went to Chennai on 2nd of september 2016
and met with Mrs Chitra (from தமிழ் மண் பதிப்பகம்)
and with Mr Arockiasamy Mohanraj, a software consultant who had come from
Bangalore and who was in charge of converting the files from their
original format to a Unicode-compatible format.
After the negociation between Eva and Mr Ilavazhagan
had been concluded, Mr Arockiasamy Mohanraj
started to work on the conversion
and on 7th of October
he sent us a collection of files.
However, those files were not useable,
because they were affected by two bugs: the ழி BUG and the ழூ BUG.
The first of these two bugs was the TOTAL ABSENCE in the files received
of the ழி UYIRMEY, which had been eliminated
by the conversion method, as can be seen
in the SAMPLE ACCESSIBLE
THROUGH CLICKING HERE!
The second of these bugs consisted in the fact
that the ழூ UYIRMEY did not always stand for itself
but was sometimes an INVOLUNTARY substitute for the ">" sign.
After a series of exchanges, Mr Arockiasamy
managed to find the cause for the bugs, and sent us
a new series of files for the TIPA, in two installments.
On 5th november 2016, we received 8 TIPA files
and on 27th november 2016 (Sunday), we received the remaining 9 TIPA files.
A preliminary (quick) conversion was made by JLC,
and the result placed at THIS URL
on the NETamil Pondy server.
The current starting point
The task at hand is now to make a more precise conversion,
and to document the method used.
The starting point is a collection of HTML files, such as the following:
(0a)
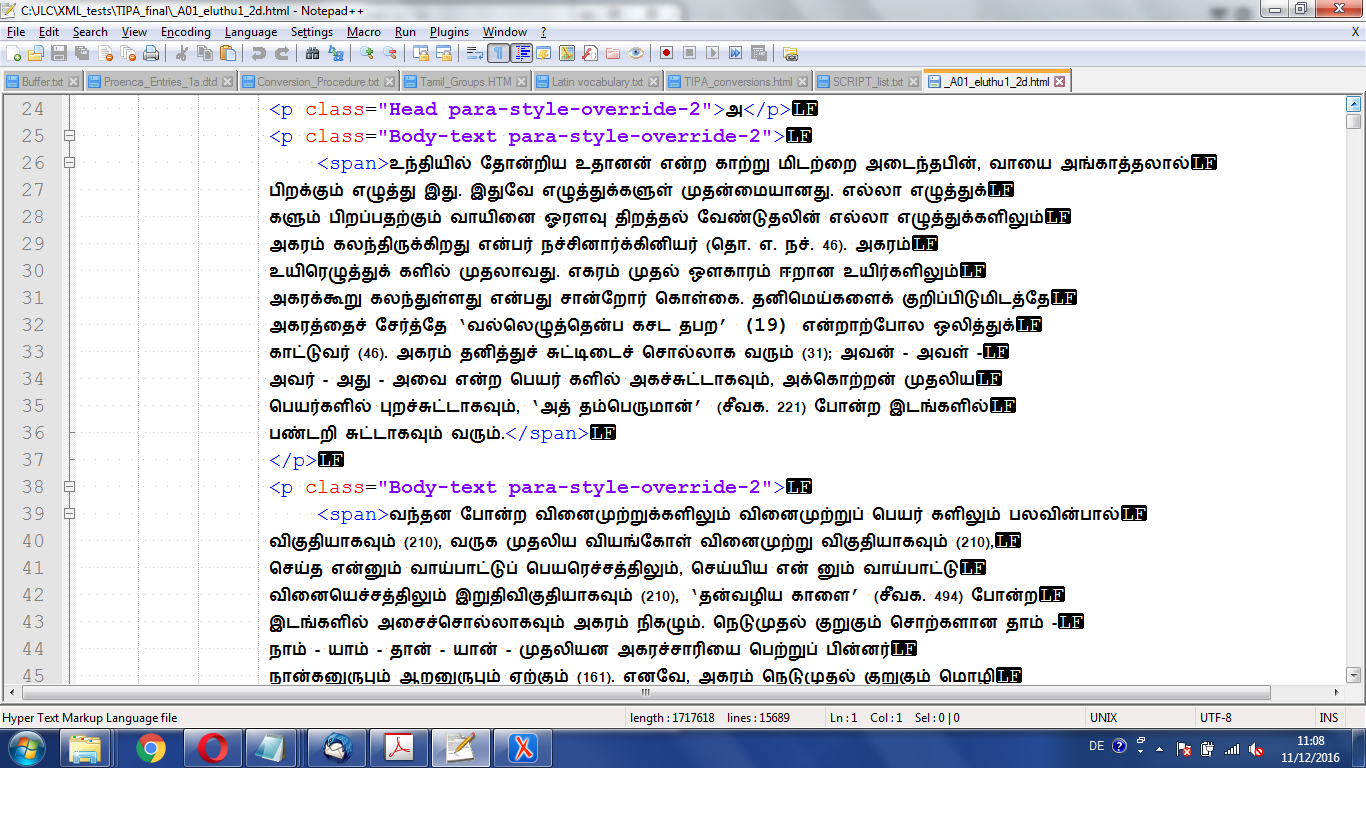
Opened with a text editor (Notepad++), the inside of the first HTML files looks like this:
(0b)
.png)
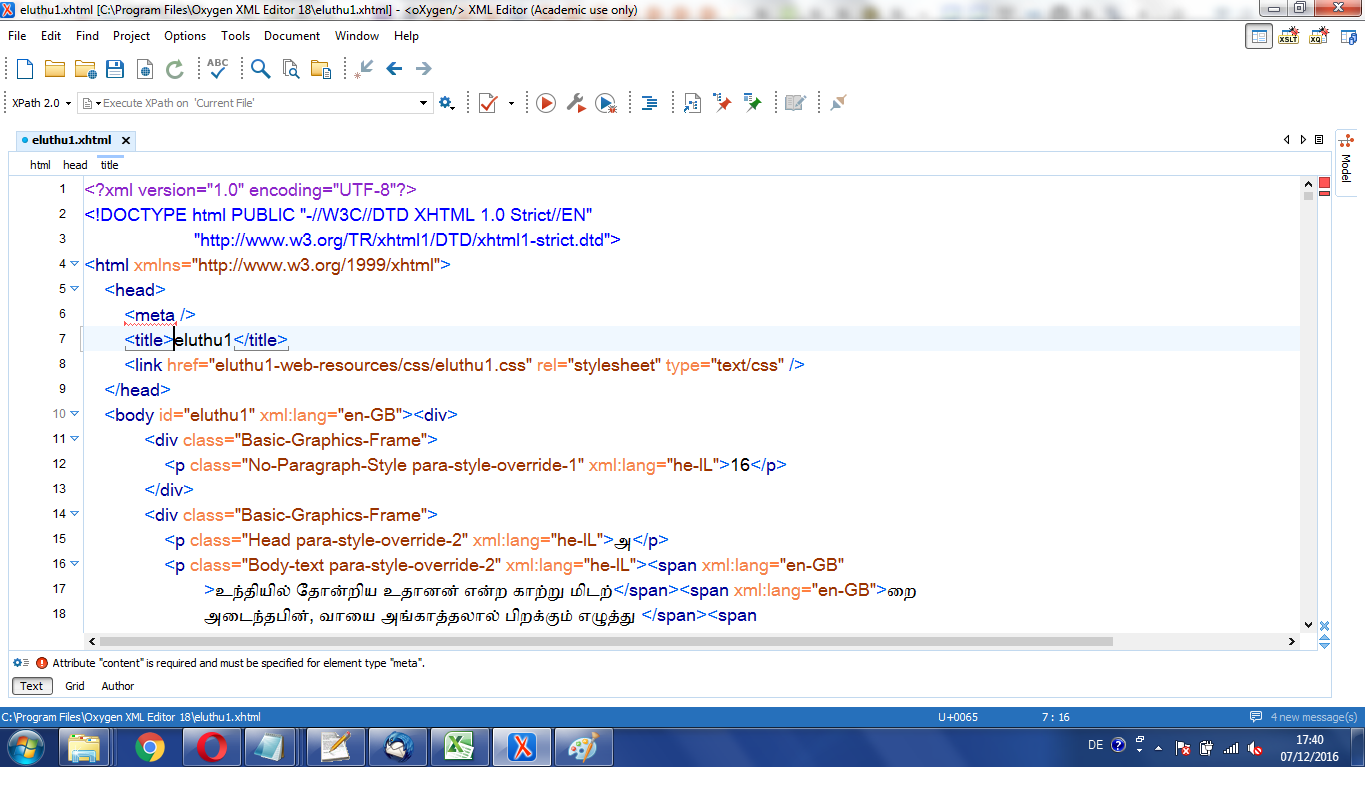
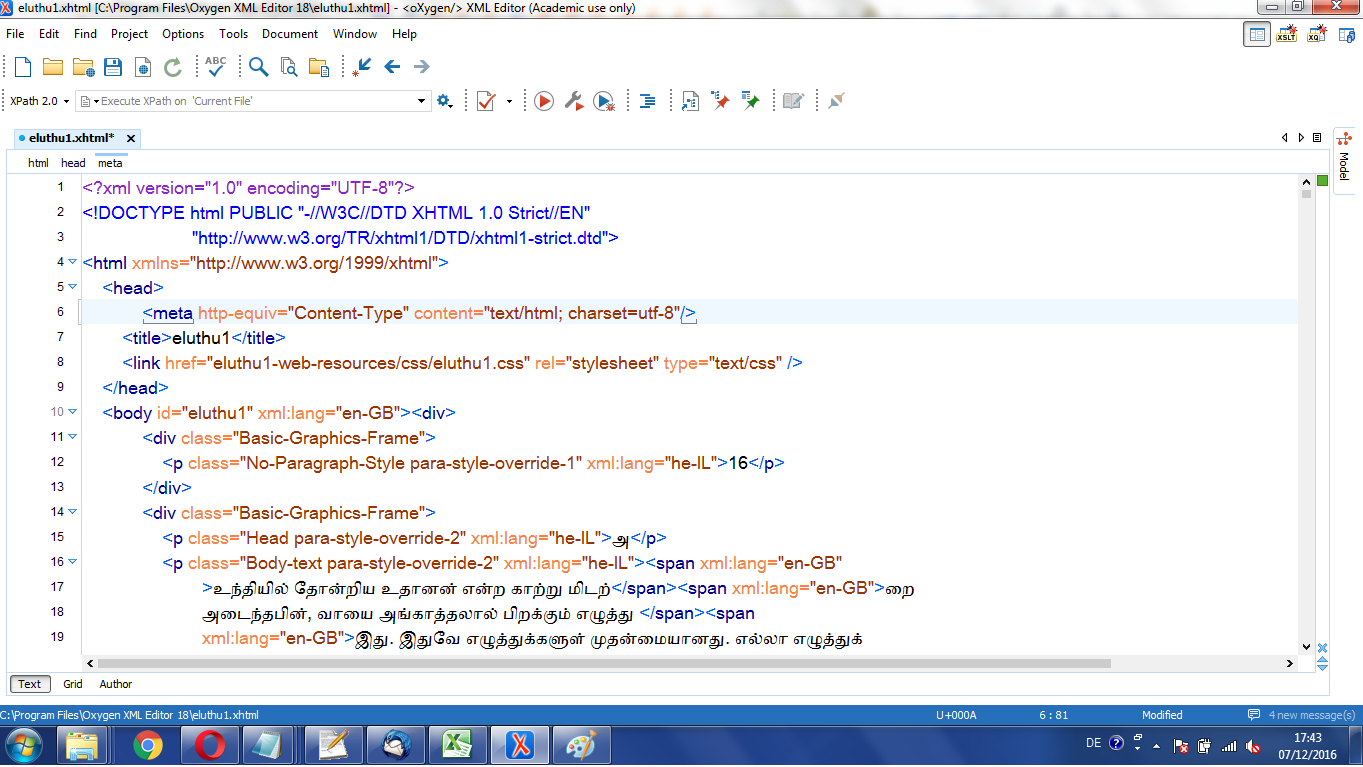
Importing the files into Oxygen
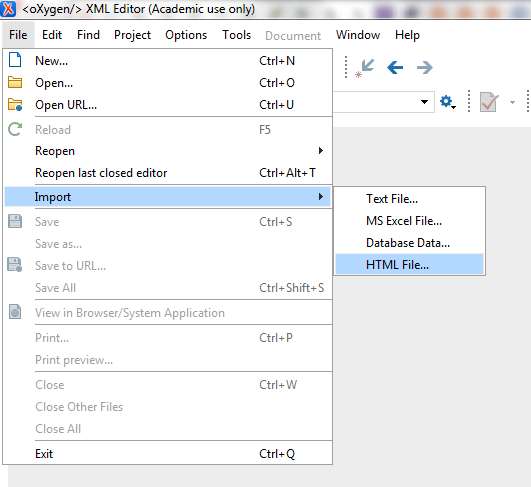
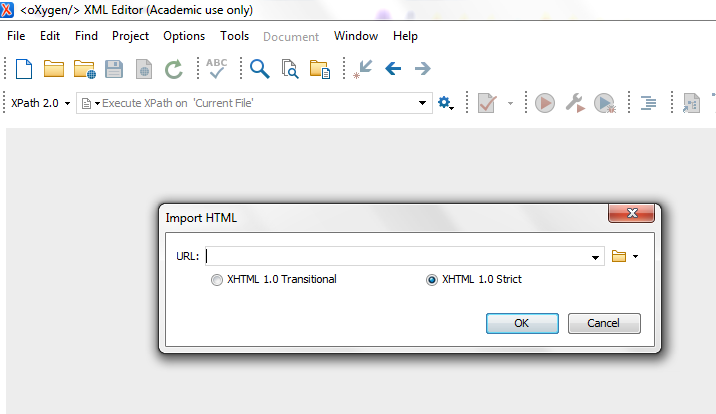
The first step in making those files more direcctly usable
consists in using the import facilities of Oxygen (a XML editor), as
illustrated by the following series of screenshots,
where the last 2 steps illustrate an adjustment
made in the <meta> tag.
(1a)
(1b)
(1c)
(1d)
(1e)
(1f)
The file is then saved under a convenient name, as in the following example:
(1g)
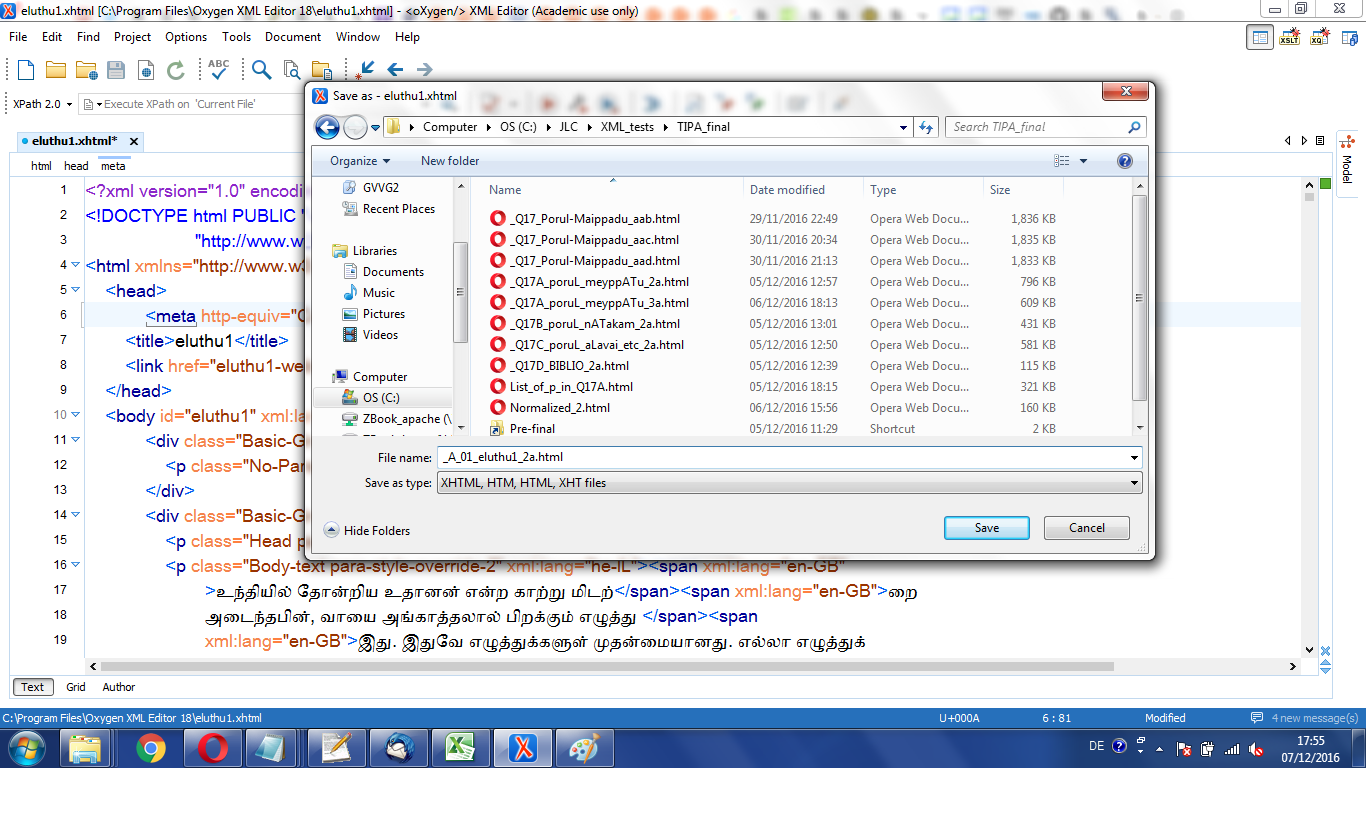
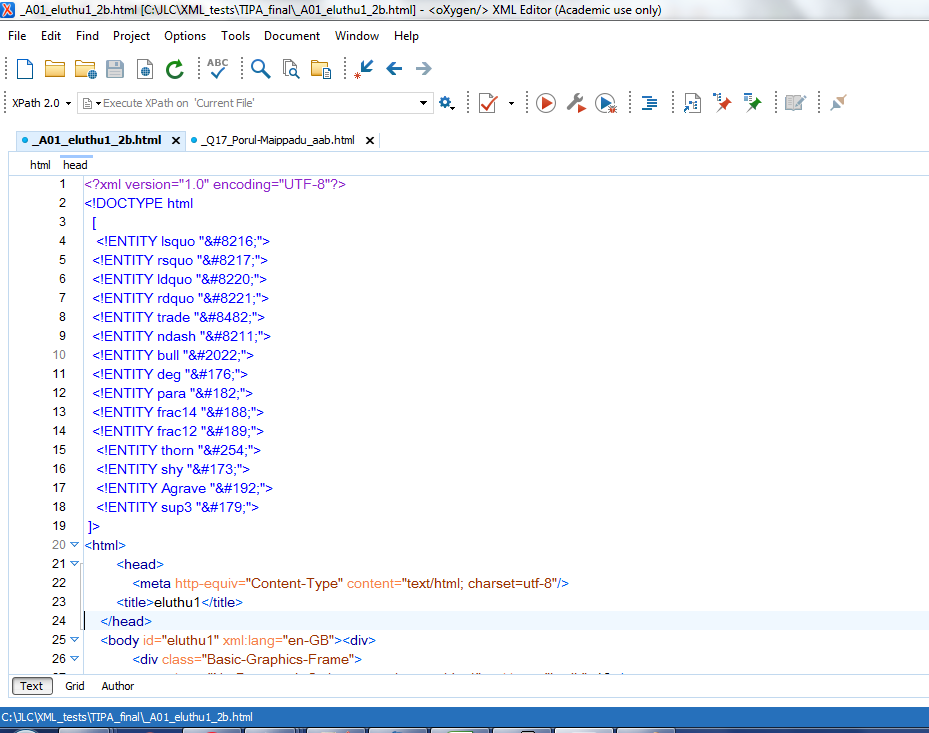
Getting rid of the HTML namespace and of the CSS dependancies
At this stage, the file which has been saved under a new name and which is open inside
the Oxygen XML editor is a file following the "XHTML 1.0 Strict" standard. This implies,
among other things, that handling this file constantly means having to be HTML "namespace" aware,
which fact greatly complicates the writing of XSLT scripts.
Therefore, my first step in handling the file,
consists in getting rid of the namespace dependency,
by modifying the current headers (visibly selected in the image below),
by new headers.
(2a)
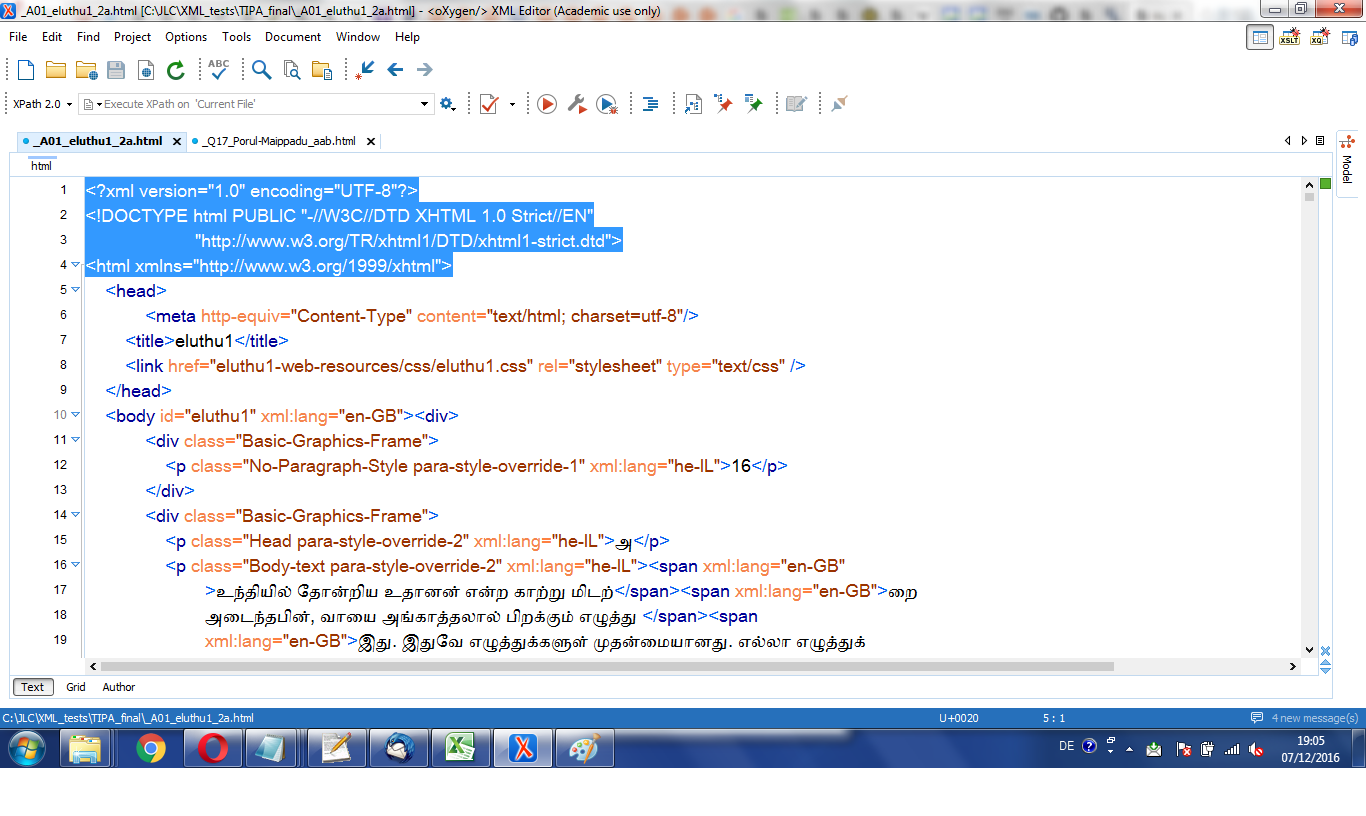
However, the removal of the (implicit) dependency on the HTML dtd,
forces us to MAKE EXPLICIT the interpretation of all the (HTML) ENTITIES
present in our current file. This is why the replacement header is as follows:
(2b)
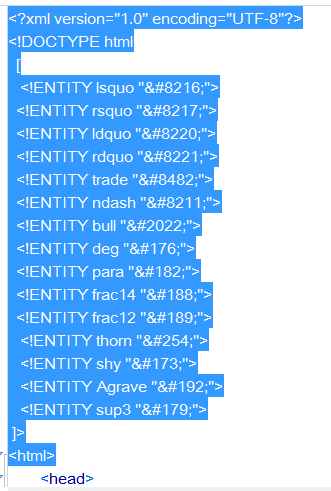
After the change of header, another component which I also decide to eliminate,
as a simplification,
is the link to the explicit CSS, as demonstrated by the following two SCREEN SHOTS:
(2c)
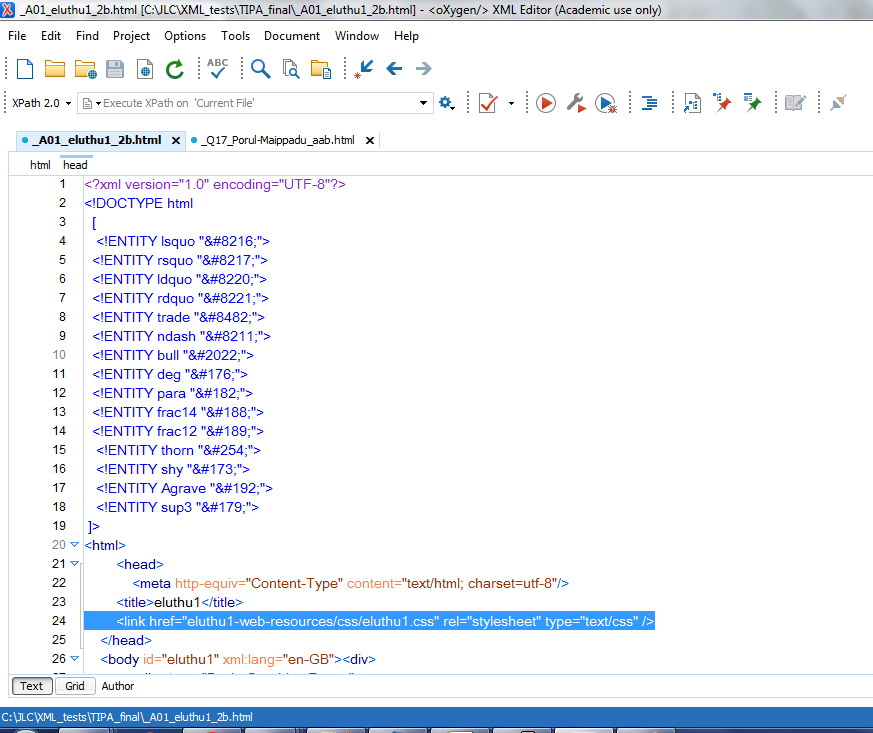
(2d)
Applying XSLT scripts on the simplified file
At this stage, we are now in a position where we can apply a series
of small XSLT scripts, in order to extract information from the simplified file,
or in order to progressively transform it. Several of those script
will include as an "imported" component, a simple script,
called "copy.xslt"
and referred to by some writers as the IDENTITY TRANSFORMATION,
which is reproduced below.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="node() | @*">
<xsl:copy>
<xsl:apply-templates select="@* | node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
<!-- ((Script Name: copy.xslt))
((copied from /XSLT Cookbook (2nd ed.)/, Sal Mangano, 2006, pp.274-275))
-->
A first example is the following script, called List_elements_in_body.xslt,
which can be applied (using Oxygen) to the simplified file _A01_eluthu1_2b.html,
whose preparation has been described in the preceding section:
<xsl:stylesheet
version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:import href="copy.xslt"/>
<xsl:output method="xml" encoding="UTF-8" indent="yes"/>
<xsl:template match="body">
<body>
<table>
<tr><th>RANK</th><th>CLASS</th></tr>
<xsl:apply-templates></xsl:apply-templates>
</table>
</body>
</xsl:template>
<xsl:template match="body//*">
<tr>
<td><xsl:value-of select="position()"/></td>
<td><xsl:value-of select="local-name()"/></td>
</tr>
<xsl:apply-templates></xsl:apply-templates>
</xsl:template>
<xsl:template match="body//text()">
<tr>
<td><xsl:value-of select="position()"/></td>
<td>TEXT</td>
</tr>
</xsl:template>
<!-- (Script Name: List_elements_in_body.xslt)
-->
</xsl:stylesheet>
When the xslt script is run on the html file, it generates a table containing 36120 rows, starting with:
| RANK |
CLASS |
| 1 |
div |
| 1 |
TEXT |
| 2 |
div |
| 1 |
TEXT |
| 2 |
p |
| 1 |
TEXT |
| 3 |
TEXT |
| 3 |
TEXT |
| 4 |
div |
| 1 |
TEXT |
| 2 |
p |
| 1 |
TEXT |
| 3 |
TEXT |
| 4 |
p |
| 1 |
span |
| 1 |
TEXT |
| 2 |
span |
| 1 |
TEXT |
| 3 |
span |
| 1 |
TEXT |
| 4 |
span |
| [.....] |
[.....] |
If we extract the content of the right column into a file
(called A01_elements.txt), we can run on it (under Linux) the following command:
sort A01_elements.txt | uniq -c > A01_elements_uniq.txt
The content of the resulting file (A01_elements_uniq.txt) will be:
41 br
302 div
3798 p
13450 span
18529 TEXT
Typically, if we extrapolate what is seen in the beginning of the file
to the totality, the <body> element seems to contain <div> elements, which contain <p> elements.
Among the <p> elements, some directly contain TEXT, whereas others contain <span> elements
which themselves contain TEXT.
Additionally, all the <p> elements seem to contain a class attribute
and a xml:lang attribute, whereas in the case of <span> elements we seem to have,
with a few exceptions (to be examined), only a xml:lang attribute.
As a preliminary exploration, I extract the list of all the attested values
for the class attribute of the <p> elements, using the following script:
<xsl:stylesheet
version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:import href="copy.xslt"/>
<xsl:output method="xml" encoding="UTF-8" indent="yes"/>
<xsl:template match="body">
<body>
<table>
<tr><th>RANK</th><th>CLASS</th></tr>
<xsl:apply-templates></xsl:apply-templates>
</table>
</body>
</xsl:template>
<xsl:template match="div">
<xsl:apply-templates></xsl:apply-templates>
</xsl:template>
<xsl:template match="p">
<tr>
<td><xsl:value-of select="position()"/>
</td><td><xsl:value-of select="@class"/></td>
</tr>
</xsl:template>
<!-- ((SCRIPT: list-class-attribute-values-for-p-elements.xslt))
-->
</xsl:stylesheet>
When this second xslt script is run on the html file,
it generates a table containing 3798 rows, starting with
| RANK |
CLASS |
| 2 |
No-Paragraph-Style para-style-override-1 |
| 2 |
Head para-style-override-2 |
| 4 |
Body-text para-style-override-2 |
| 6 |
Body-text para-style-override-2 |
| 8 |
subhead |
| 10 |
Body-text para-style-override-2 |
| 12 |
Body-text para-style-override-2 |
| 14 |
subhead |
| 16 |
Body-text para-style-override-2 |
| 18 |
Body-text para-style-override-2 |
| 20 |
Body-text para-style-override-2 |
| 22 |
Body-text para-style-override-2 |
| 24 |
Body-text para-style-override-2 |
| 26 |
Body-text para-style-override-2 |
| 28 |
Body-text para-style-override-2 |
| 30 |
Body-text para-style-override-2 |
| 32 |
Body-text para-style-override-2 |
| 34 |
Body-text para-style-override-2 |
| 36 |
Body-text para-style-override-2 |
| 38 |
Body-text para-style-override-2 |
| 40 |
Body-text para-style-override-2 |
| 42 |
Body-text para-style-override-2 |
| 44 |
Body-text para-style-override-2 |
| 46 |
Body-text para-style-override-2 |
| 48 |
subhead |
| 50 |
Body-text para-style-override-2 |
| 52 |
subhead |
| 54 |
Body-text para-style-override-2 |
| [.....] |
[.....] |
As previously, I copy the right column of this chart to a file (called A01_p_styles.txt) and run a small script:
sort A01_p_styles.txt | uniq -c > A01_p_styles_uniq.txt
The result is a list of 97 distinct items, which is:
1 bodyIN1 para-style-override-11
1 bodyIN1 para-style-override-14
2 bodyIN1 para-style-override-15
97 bodyIN1 para-style-override-2
3 bodyIN1 para-style-override-23
1 bodyIN1 para-style-override-42
1 bodyIN1 para-style-override-44
3 bodyIN1 para-style-override-45
2 bodyIN1 para-style-override-46
8 bodyIN1 para-style-override-47
1 bodyIN1 para-style-override-6
1 bodyIN1 para-style-override-8
2 bodyIN2 para-style-override-12
1 bodyIN2 para-style-override-15
8 bodyIN2 para-style-override-17
58 bodyIN2 para-style-override-2
8 bodyIN2 para-style-override-20
4 bodyIN2 para-style-override-21
15 bodyIN2 para-style-override-22
2 bodyIN2 para-style-override-23
1 bodyIN2 para-style-override-27
4 bodyIN2 para-style-override-28
5 bodyIN2 para-style-override-31
1 bodyIN2 para-style-override-32
3 bodyIN2 para-style-override-33
3 bodyIN2 para-style-override-34
10 bodyIN2 para-style-override-9
2 bodylN3 para-style-override-12
1 bodylN3 para-style-override-16
5 bodylN3 para-style-override-2
3 bodylN3 para-style-override-21
2 bodylN3 para-style-override-28
1 bodylN3 para-style-override-29
2 bodylN3 para-style-override-8
2 bodylN3 para-style-override-9
14 Body-text para-style-override-12
72 Body-text para-style-override-15
1738 Body-text para-style-override-2
5 Body-text para-style-override-21
7 Body-text para-style-override-23
16 Body-text para-style-override-24
1 Body-text para-style-override-25
16 Body-text para-style-override-31
2 Body-text para-style-override-32
1 Body-text para-style-override-39
2 Body-text para-style-override-40
1 Body-text para-style-override-41
17 Body-text para-style-override-49
2 Body-text para-style-override-50
1 Body-text para-style-override-51
10 Body-text para-style-override-52
11 Body-text para-style-override-8
17 Body-text para-style-override-9
8 example1 para-style-override-15
176 example1 para-style-override-2
2 example1 para-style-override-21
1 example1 para-style-override-23
7 example1 para-style-override-31
4 example para-style-override-15
1 example para-style-override-19
149 example para-style-override-2
2 example para-style-override-36
9 example para-style-override-37
1 example para-style-override-38
3 example para-style-override-53
1 example para-style-override-54
6 example para-style-override-55
2 example para-style-override-56
19 example para-style-override-8
2 example para-style-override-9
14 Head para-style-override-2
1 Head para-style-override-43
1 Head para-style-override-48
3 nobody para-style-override-2
296 No-Paragraph-Style para-style-override-1
2 No-Paragraph-Style para-style-override-57
1 No-Paragraph-Style para-style-override-58
1 padal1 para-style-override-18
11 padal1 para-style-override-2
17 padal2 para-style-override-15
99 padal2 para-style-override-2
3 padal2 para-style-override-23
13 padal para-style-override-2
25 right para-style-override-2
1 right para-style-override-31
2 sub
4 sub1
645 subhead
1 subhead para-style-override-10
1 subhead para-style-override-13
20 subhead para-style-override-26
2 subhead para-style-override-3
6 subhead para-style-override-30
2 subhead para-style-override-35
28 subhead para-style-override-4
5 subhead para-style-override-5
4 subhead para-style-override-7
However, 94 among those items are further analysable as the combination
of a semantics prefix and a format specification,
whereas 3 items (namely, "sub", "sub1" and "subhead")
contain only the semantics part:
The chart for the semantics component distribution is as follows
12 bodyIN1
15 bodyIN2
8 bodylN3
18 Body-text
12 example
5 example1
3 Head
1 nobody
3 No-Paragraph-Style
1 padal
2 padal1
3 padal2
2 right
1 sub
1 sub1
10 subhead
The chart for the format specification distribution is as follows
1 para-style-override-1
12 para-style-override-2
1 para-style-override-3
1 para-style-override-4
1 para-style-override-5
1 para-style-override-6
1 para-style-override-7
4 para-style-override-8
4 para-style-override-9
1 para-style-override-10
1 para-style-override-11
3 para-style-override-12
1 para-style-override-13
1 para-style-override-14
6 para-style-override-15
1 para-style-override-16
1 para-style-override-17
1 para-style-override-18
1 para-style-override-19
1 para-style-override-20
4 para-style-override-21
1 para-style-override-22
5 para-style-override-23
1 para-style-override-24
1 para-style-override-25
1 para-style-override-26
1 para-style-override-27
2 para-style-override-28
1 para-style-override-29
1 para-style-override-30
4 para-style-override-31
2 para-style-override-32
1 para-style-override-33
1 para-style-override-34
1 para-style-override-35
1 para-style-override-36
1 para-style-override-37
1 para-style-override-38
1 para-style-override-39
1 para-style-override-40
1 para-style-override-41
1 para-style-override-42
1 para-style-override-43
1 para-style-override-44
1 para-style-override-45
1 para-style-override-46
1 para-style-override-47
1 para-style-override-48
1 para-style-override-49
1 para-style-override-50
1 para-style-override-51
1 para-style-override-52
1 para-style-override-53
1 para-style-override-54
1 para-style-override-55
1 para-style-override-56
1 para-style-override-57
1 para-style-override-58
We now examine the "class" attribute values
which are sometimes taken by the <span> elements,
by means of another script, which is as follows:
<xsl:stylesheet
version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:import href="copy.xslt"/>
<xsl:output method="xml" encoding="UTF-8" indent="yes"/>
<xsl:template match="body">
<body>
<table>
<tr><th>RANK</th><th>CLASS</th></tr>
<xsl:apply-templates></xsl:apply-templates>
</table>
</body>
</xsl:template>
<xsl:template match="div">
<xsl:apply-templates></xsl:apply-templates>
</xsl:template>
<xsl:template match="text()">
</xsl:template>
<xsl:template match="p">
<xsl:apply-templates></xsl:apply-templates>
</xsl:template>
<xsl:template match="span">
<tr>
<td><xsl:value-of select="position()"/>
</td><td><xsl:value-of select="if (exists(@class)) then @class else 0"/></td>
</tr>
</xsl:template>
<!-- ((SCRIPT: list-class-attribute-values-for-span-elements.xslt))
-->
</xsl:stylesheet>
This again generates a chart, containing 13450 rows,
among which 12606 contain the value 0 in the right column,
which indicates the absence of a class attribute.
The remaining 844 rows are distributed in the following manner:
389 char-style-override-1
133 char-style-override-2
57 char-style-override-3
126 char-style-override-4
22 char-style-override-5
37 char-style-override-6
10 char-style-override-7
2 char-style-override-8
1 char-style-override-9
10 char-style-override-10
3 char-style-override-11
1 char-style-override-12
14 char-style-override-13
1 char-style-override-14
2 char-style-override-15
1 char-style-override-16
34 char-style-override-17
1 char-style-override-18
Examining the entities (and giving some of them a more suitable interpretation)
At this stage, before we start to simplify the structure and to get rid of the unnecessary
elements of formating, a preliminary task consists in examining the entities
enumerated inside the current header,
in order to provide a proper set of equivalence.
The list (compiled on the basis of the 17 books of the TIPA)
currently runs as follows:
<!ENTITY lsquo "‘"> (i.e. "‘")
<!ENTITY rsquo "’"> (i.e. "’")
<!ENTITY ldquo "“"> (i.e. "“")
<!ENTITY rdquo "”"> (i.e. "”")
<!ENTITY trade "™"> (i.e. "™")
<!ENTITY ndash "–"> (i.e. "–")
<!ENTITY bull "ߦ"> (i.e. "ߦ")
<!ENTITY deg "°"> (i.e. "°")
<!ENTITY para "¶"> (i.e. "¶")
<!ENTITY frac14 "¼"> (i.e. "¼")
<!ENTITY frac12 "½"> (i.e. "½")
<!ENTITY thorn "þ"> (i.e. "þ")
<!ENTITY shy "­"> (i.e. "SOFT HYPHEN")
<!ENTITY Agrave "À"> (i.e. "À")
<!ENTITY sup3 "³"> (i.e. "³")
However, in the case of the 1st file, not every entity is found.
There are no attestations of "þ", "­", "À" and "³".
What we find is:
- 2 occurrences of the trade ENTITY ("™" = "™") which have to be replaced by "ண"
- 1 occurrence of the ndash ENTITY ("–" = "–") which is suppressed in normalizing
- 1 occurrence of the bull ENTITY ("•" = "•") which is replaced by ஶ் (palatal s = grantha ś)
- 4 occurrences of the deg ENTITY ("°" = "°"), which have to be replaced by ஸ்
- 7 occurrences of the para ENTITY ("¶" = "¶"), which are (temporarily) replaced by the string "{{special_puLLi}}"
As for remaining 6 entities ("‘" = "‘"; "’" = "’";
"“" = "“";
"”" = "”"; "¼" = "¼"; "½" = "½"),
they are used in a proper way,
and must simply be translated automatically. Therefore, after applying the corrections,
the header for the corrected html file
(called _A01_eluthu1_2c.html) contains simply, in the end:
<!ENTITY lsquo "‘"> (i.e. "‘")
<!ENTITY rsquo "’"> (i.e. "’")
<!ENTITY ldquo "“"> (i.e. "“")
<!ENTITY rdquo "”"> (i.e. "”")
<!ENTITY frac14 "¼"> (i.e. "¼")
<!ENTITY frac12 "½"> (i.e. "½")
Getting rid of the "xml:lang" attribute
At this stage, we are now ready to get rid of the xml:lang attribute,
by using the following script, which filters out unwanted elements
<xsl:stylesheet
version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:import href="copy.xslt"/>
<xsl:output method="xml" encoding="UTF-8" indent="yes"/>
<xsl:template match="body">
<body>
<xsl:apply-templates></xsl:apply-templates>
</body>
</xsl:template>
<xsl:template match="p">
<p><xsl:attribute name="class"><xsl:value-of select="@class"/></xsl:attribute><xsl:apply-templates></xsl:apply-templates></p>
</xsl:template>
<xsl:template match="span[@class]">
<span><xsl:attribute name="class"><xsl:value-of select="@class"/></xsl:attribute><xsl:apply-templates></xsl:apply-templates></span>
</xsl:template>
<xsl:template match="span">
<SPAN><xsl:apply-templates></xsl:apply-templates></SPAN>
</xsl:template>
<!-- (Script Name: filtering_out_xml_lang_attributes_in_p_and_span.xslt)
-->
</xsl:stylesheet>
It must be noted, however, that we are playing a trick, by using two different
spellings for the <span> element, which we write as <SPAN> (with Upper-case),
when it does not have a "class" attribute. This causes Oxygen to protest,
but allows us to concatenate the strings of consecutive <SPAN> elements,
using for our comfort the Notepad++ editor,
searching for the following regular expression (to be replaced by the EMPTY string).
</SPAN>\s*<SPAN>
After that, in order to produce a file acceptable to the Oxygen editor,
we still have to:
- get rid of the empty <SPAN/> elements
- replace all the remaining UPPERCASE "SPAN>" strings by (lowercase) "span>" strings
The final file will be saved under a new name (in this case: _A01_eluthu1_2d.html)
Seen with the Notepad++ editor, its appearance is now as follows:
(3a)